Notes:
- 安排fork和execve两步的目的:允许子进程处理文件描述符,完成对标准输入输出的重定向
- XV6心得:当某个锁可能被某个中断处理函数获得时, acquire 这个锁之前需禁用中断
Ch1 绪论
- 系统:由一群有关联的个体组成,根据某种规则运作,能完成个别元件不能单独完成的工作的群体
- OS定义:在应用和硬件之间的一层软件;给上层应用提供硬件的抽象;对底层硬件进行管理:共享和隔离
- OS能做什么:构建系统环境,让硬件可用;资源管理(公平);系统保护(安全并行);硬件处理(包装)
计算机发展的阶段
OS是函数库,批处理
分时共享Unix、MULTICS
PC典型的UNIX系统结构
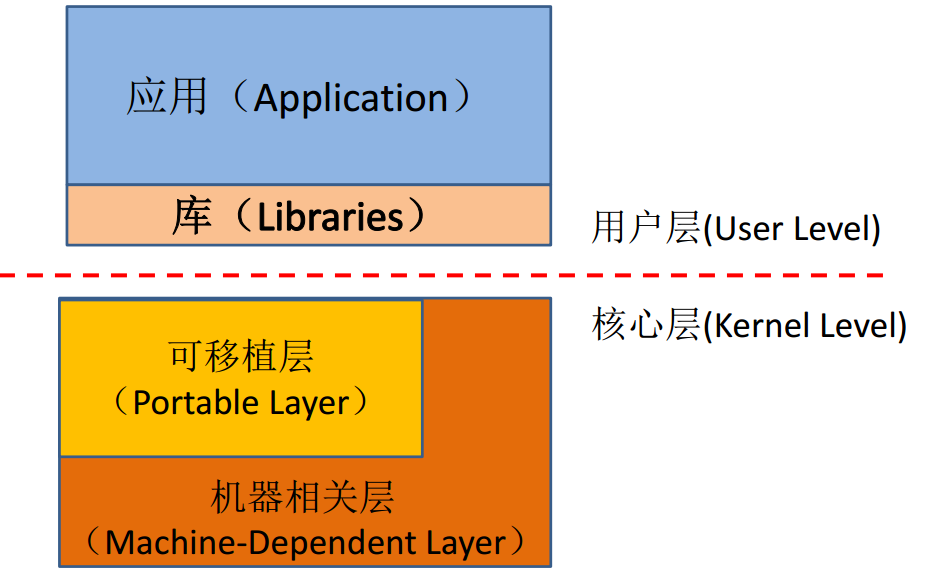
应用:程序员经编译的程序
库:精心设计的代码,预编译对象,链接器引入,加载时必须定位
可移植层:系统调用功能的集合
机器相关层:启动初始化、中断例外、IO设备、内存处理器调度、模式切换- Loader流程:
读ELF文件
放置代码(指令序列)、Initialized data、堆、栈
动态链接到共享库栈:编译器布局,局部寻址 堆:链接器、loader确定起始地址;通过库函数malloc管理;可能随机分配 全局数据+代码:编译器静态分配产生符号;链接器重定位;加载器完成内存的布局
准备好OS核心运行应用 - OS的组成
处理器管理:分时复用、同步、公平 - 调度器
内存管理:效率公平
IO设备管理
文件系统:可靠性 效率
窗口系统GUI
启动
上电、处理器Reset、跳转BIOS初始化、加载bootloader、加载OS OS的结构
一体结构(宏内核)
共享内核地址空间、效率高、不稳定、不灵活
Win Linux
微内核
操作系统服务作为常规进程,用户通过消息获取服务
灵活、低故障、低效、不方便共享数据
MacOS
库操作系统
App直接通过库与底层硬件交互
效率高 通用性差
虚拟机OS状态切换
特权态:常规指令、特权指令、访问用户内存、访问核心内存
切换方式:
系统调用
操作系统API
传参方式:寄存器、堆栈、内存向量(数组)
种类:进程管理、内存管理、文件管理了、设备管理、通信
按功能划分:内核brk粗粒度划分给库;库细粒度malloc管理内存
流程:切到内核栈;保存上下文;检查R0;跳到R0地址;结果存到R31;恢复上下文;切换用户栈;iret
中断/异常中断源:硬件、软件INT 例外:程序错误、软件生成INT、硬件检测例外- 科研中的四种能力
系统经济学观
全局系统观、经济学理念(降低成本)
剥茧抽丝
全系统栈调试能力
抽象建模
技术发展史 - 经典延时
分支预测 5ns
L1 1ns
互斥锁 25ns
主存 0.1us
HDD寻道 10ms
SSD 10us
Ch2 进程与线程
- 进程Def:一个具有一定独立功能的程序在一个数据集合上的一次动态执行过程
- 进程的并行性:虚拟化CPU、IO计算交叠、CPU并行性
- 进程的表示:进程控制块PCB
PCB是进程在内核中的表示
包含:状态、寄存器、内存管理(栈、页表、段)、IO文件管理(通信端口、目录、文件描述符) - 原语:
创建和终止exec fork wait kill
信号
操作 yield
同步 - 进程的状态切换
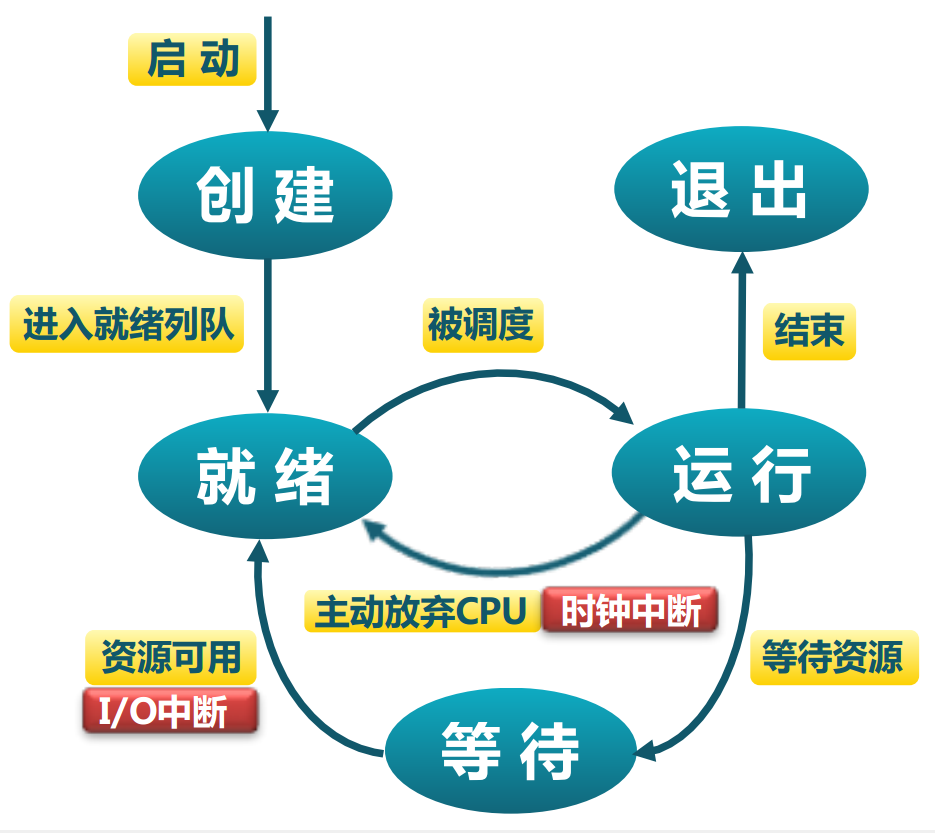
创建:系统初始化时、用户请求时
退出:正常退出、出错退出、致命错误强制退出、被其他进程杀死 - 线程Def 线程是进程的一部分,描述指令流执行状态,是CPU调度的基本单位
线程在同一地址空间 可以共享变量
原因:进程切换系统开销大,同应用多个活动
CPU利用率=1-pn p=IO操作与停留在内存的时间比 - 线程切换vs进程切换:
线程:TLB共享,不变;Cache不动,硬件自动替换
进程:需刷新Cache,保存内存影响(TLB内的内存访问位) - TCB内容
状态、寄存器、EIP、栈、代码、共享所有权限
除了地址空间和堆共享 - 线程的分类
用户线程
由一组用户级的线程库函数来完成线程的管理,包括线程的创建、终止、同步和调度等。每个进程有运行时系统和用户态TCB表
优点:快捷、高效、自己的调度算法、可扩展
缺点:阻塞系统调用难实现、无时钟中断、页面故障问题
内核线程
通过系统调用实现的线程机制,由内核完成线程的创建、终止和管理
TCB表在内核中
开销大
轻量级进程
内核支持的用户线程。一个进程可有一个或多个轻量级进程,每个轻权进程由一个单独的内核线程来支持。
TCB和PCB约等于
一对一:每一个用户级线程拥有自己的内核栈
多对一:一个进程所有线程共享内核栈内存利用率高、系统服务可并行、可多处理器、复杂度高 - 调度目的
公平性(不饥饿)
批处理:吞吐量、CPU占用率、周转时间
交互式系统:响应时间、均衡性
实时系统:满足截止时间、可预测性 - 调度器工作流程
保存当前进程线程状态
选择下一个待运行的进程线程
分派 - 调度算法
先到先服务FCFS
优点:简单 缺点:CPU利用低、平均响应时间波动大
最短时间优先STCF、最短剩余时间优先(用于抢占)SRTCF
优点:平均响应时间短
缺点:不公平、饥饿;需要询问时间
时间片轮转算法RR
FCFS的抢占式 公平
大时间片:等待时间长
小时间片:响应时间快、大量上下文切换
虚拟轮转算法VRR
IO密集型进入辅助队列FIFO,辅助队列优先级更高
公平
多级队列MQ
就绪队列分子队列,不同调度算法,不同时间片额度
多级反馈队列MLFQ
用完时间片则下降优先级,IO密集型保持高优先级
彩票调度
避免饥饿的SRTCF;公平
公平共享调度FSS
用户组有优先级
公平第一位 - 多处理器调度
协同调度(多进程、同进程的多线程)
专用处理器分配(线程专用CPU,直到处理完成) - 实时调度
可调度条件(接纳控制): Ci计算时间 Ti周期
算法:
速率单调调度:进程的优先级等于出现频率,越高越好
必须周期性进程
最早最终时限优先调度EDS
需要进程宣布最终时限,不一定周期性进程
进程在最终时限来临前会抢占当前进程
BSD多队列调度
Pi = base + (CPUi – 1) /2 +nice
CPUi = (Ui + CPUi – 1) / 2
Ui进程第i段时间利用率
Ch3 同步与通信
- 并发进程需要信息同步(共享资源)和数据传输(管道)
- 临界区:保证原子操作
实现:基于软件、硬件中断、原子操作指令与互斥锁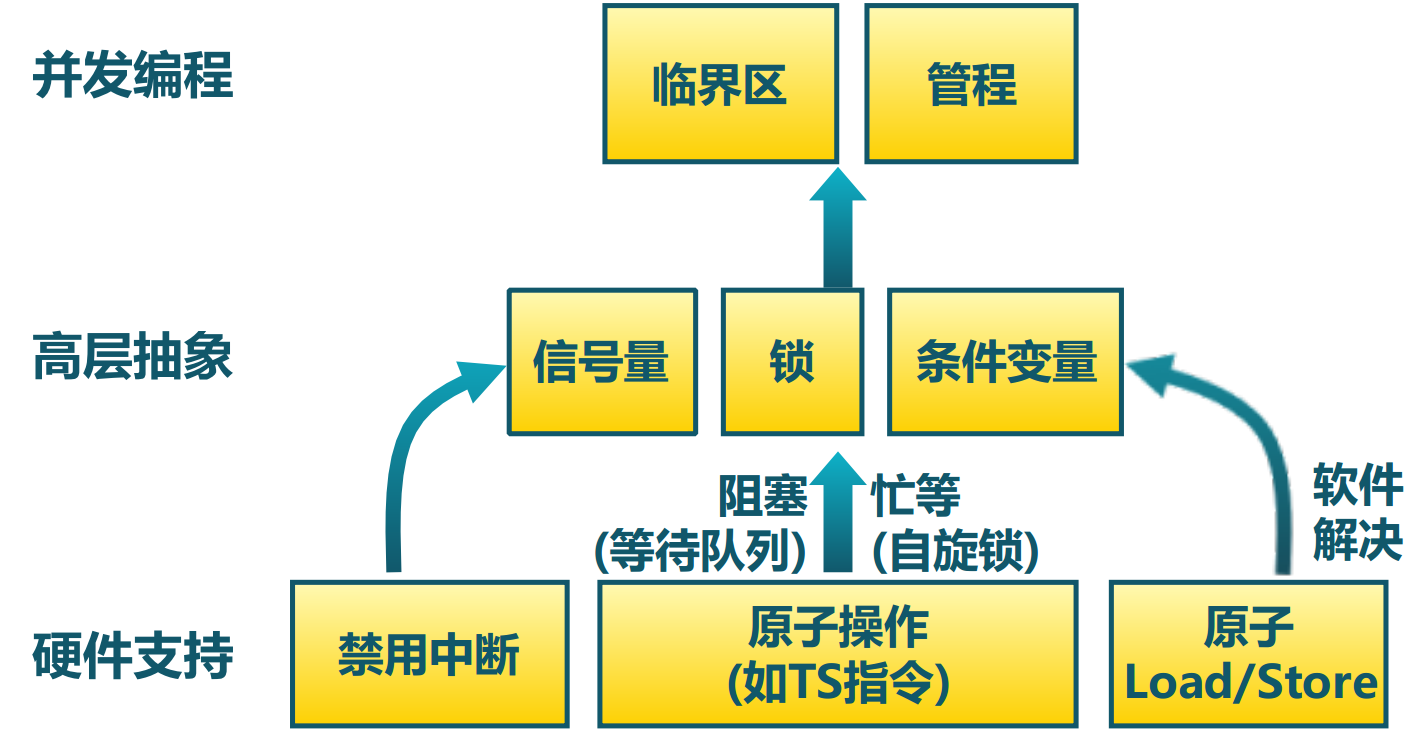
- 软件方案:
特点:复杂(需共享数据);忙等浪费CPU
LockTwo:
while (turn ≠ i); //turn表示允许进入临界区的线程
CRITICAL
turn = j;
满足忙等 不满足空闲则入
LockOne:
Flag[id]表示线程id是否在临界区
While (flag[j]);
flag[i]=1;
CRITICAL
Flag[i] = 0;
不满足忙等
解决:先置1后循环检查,满足忙等 不满足空闲则入
Peterson算法:
Turn 该谁进入临界区;flag[id]线程id是否准备好
Falg[id] = 1;
Turn = j;
While (flag[j] && turn == j);
CRITICAL
Flag[i] = false;
空闲则进、有忙等但不饥饿
Dekkers算法
N线程:线程退出时把turn++;线程Ti要等从turn 到i-1的线程都退出临界区后访问临界区
- 禁用中断
延迟处理外部事件,在acquire和release里禁止上下文切换
缺点:只适用单核;进程无法被停止,导致饥饿;临界区太长无法响应硬件 - 原子操作指令
TAS:取值、存1、返回读数
Exchange:交换
LL-SC:检测是否被修改过
优点:使用N处理器任意进程数同步;简单易证
缺点:忙等、饥饿、死锁(拥有临界区的低优先级进程) - 死锁Def:一个进程集合死锁,如果集合中所有进程都在等待一个事件,且等待的事件只能由集合中其它进程触发
- 资源分配图
进程A持有资源R
进程B请求资源S
死锁 = 资源分配图里的环 - 死锁条件
互斥:所有资源恰分配给一个进程
占有和等待:持有资源的进程可以请求新资源
不可抢占:资源不可被抢走
环路等待:进程以环路的形式等待 - 死锁的策略
忽略问题
检测并修复
杀死、回滚
动态避免
银行家算法 Need = Max – Allocation
安全状态:未发生死锁+存在让所有进程能完成的调度方案
预防
避免互斥 假脱机虚拟化
避免占有 两阶段加锁(先全部加锁)
抢占
对资源请求制定顺序id,请求升序提出(或不能请求比当前占有资源id低的资源)最流行 - 信号量
表示系统资源的剩余量
原子操作:P(Down)若非正,添加到等待队列;减一
V(Up)加一
使用:互斥访问(信号量为1);条件同步(多线程同步) - 生产者消费者
信号量实现:mutex(1), fullBuffer, emptyBuffer
存:notFull->P; mutex->P; Add(c); mutex->V; notEmpty->V
管程实现:存:
lock->acquire();
while (count==n) notFull.wait();
Add c
notEmpty.signal();
lock->release(); - 管程
用于多线程互斥访问共享资源的程序结构
Signal之后的选择:Hoare被唤醒的进程立即执行
Hanson:退出管程 signal必须是最后一行语句
Mesa:继续执行 - 条件变量
等待:加入等待队列、释放锁、调度、上锁
Singal:移出等待队列、唤醒 - 屏障Barrier
指定屏障变量,广播给其他n-1进程,若变量值达到n则继续
在并行计算机上的应用:多播网络、计数逻辑、用户级屏障变量 - 哲学家就餐问题
信号量实现:
信号量初始化为1
奇数编号:先拿左叉子再拿右叉子;偶数编号相反;最后放叉子先左后右 - 读者-写者问题
读写互斥、写写互斥
信号量实现:
WriteMutex初识为1,表示读写的互斥
CountMutex 修改Rcount时的互斥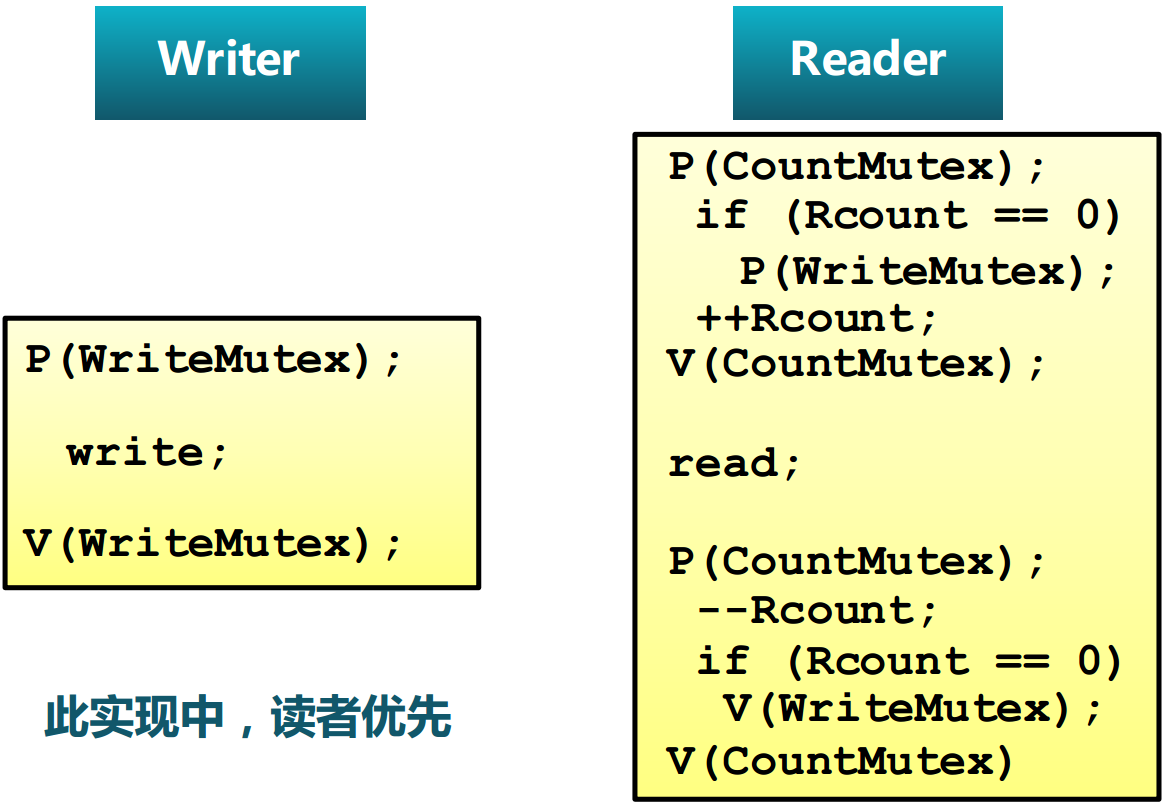
管城实现 Sync03 P39-40 - 进程间通信
流程:建立通信链路、Send/Recv交换数据
目的主体:pid, file, port
途经:
消息队列
由OS维护,以字节序列为基本单位的间接通信机制
每个消息是一个字节序列
相同标志的消息构成FIFO
共享内存
OS把同一个物理内存区域同时映射到多个进程的内存地址空间
优点:快速方便
缺点:需要额外的同步机制协调数据访问
管道
进程间基于内存文件的通信机制
子进程继承文件描述符
信号
进程间的软件中断通知和处理机制
信号接收处理方式:捕获(执行进程指定的处理函数)、忽略(执行OS的缺省处理)、屏蔽(禁止进程接收处理信号)
缺点:传送信息量小;只有一个类型
流程:进程向OS注册信号处理函数;OS分发信号到进程的信号处理函数;执行信号处理函数
设计考虑:
缓冲
直接通信:只有一方有缓冲
间接通信:信箱(允许多对多通信),需要缓冲区、互斥锁、条件变量
同步发送:若资源忙则阻塞;启动数据传输后,直到源缓冲用完后再阻塞
异步发送:结束时需要应用检查状态,或者向应用发信号
异步接收:有消息则返回数据,无消息则返回状态(用接收线程或事件处理)
同步最常见,异步可以并发,要精心设计
消息丢失:确认/超时检测、乱序(序列号)
消息损坏:重发、检验码CRC - 例:键盘输入
键盘输入->中断处理器->生成mbox消息
Ch4 虚拟内存
- 存储层次
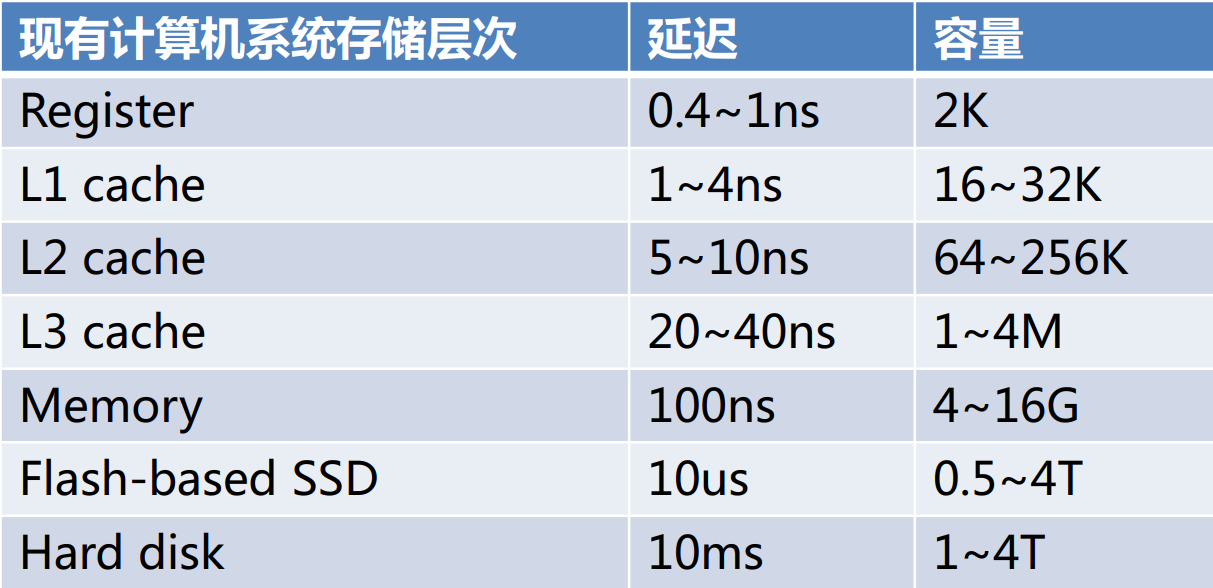
- 需求
应用透明(运行在不同的内存大小)
扩展内存
进程保护
多进程共享 - 虚拟内存
CPU和进程看到虚地址
内存和IO设备看到物理地址
优点:灵活、简单、高效
映射粒度
字节映射,映射表大小=程序大小
映射实现方式
软件:无内存保护
MMU
OS负责维护MMU:内存管理、进程切换、异常处理 - 找空闲片段的方法:首次适配、下次适配(继续)、最优适配(找最小段)、最差适配、快速适配(分段,类似伙伴系统)
- 映射方式
基址+长度
不足:外部碎片、进程难增大、难共享内存
分段
每个进程有段表(seg, valid, size, base)
段错误:valid=0;越界:memory violation
段间离散,段内连续
不足:外部碎片
流程:虚拟地址=Segment||Offset,Segment根据段表找到Base,Base和Offset物理加
切换进程:切换段表和指向段表的内核指针
分页
使用固定大小的内存单元,按需加载
每个进程有页表,记录虚页到物理页的映射
好处:分配简单、易共享、按页保护
不足:页表太大、页表项很多空闲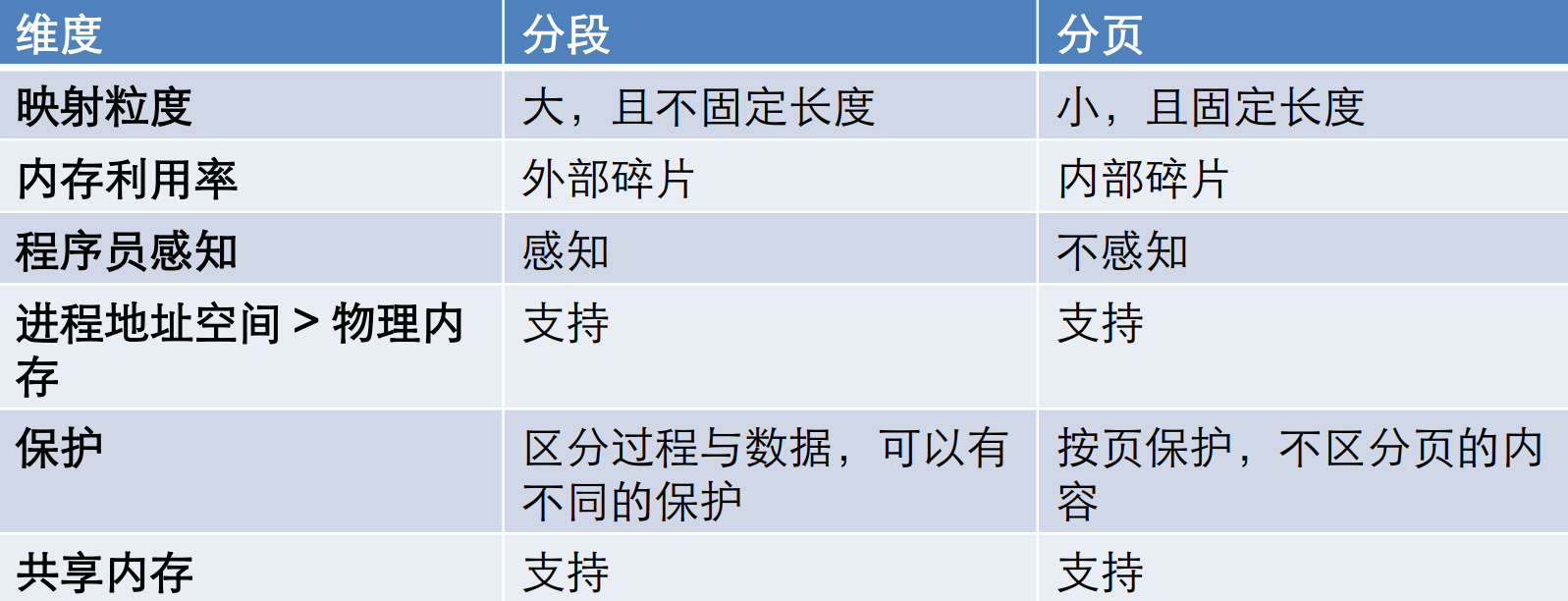
页表项 – 4B
PFN
P位:在不在内存
R/W U/S: User or Supervisor
A位:标识是否被访问
D位:是否为脏
设页大小4KB,每个进程的页表项大小为4MB
段页式
先划分为若干段,每个段分页,段表记录页表地址
虚拟地址=Vseg||VPage||offset
多级页表
设分为10||10||12
一级页表管1024个二级页表
二级页表有1024项,每项映射一个页
进程的页表的大小:4B1024+4B1024=8KB
反向页表
按物理页索引,记录物理页对应的进程ID和虚页
地址转换:哈希查找
缺点:维护哈希链的开销
适用于虚拟内存大、物理内存小 - TLB
VP, PP, valid, 访问控制位;pid,RM(用于页替换),Cache
流程
VA给MMU,MMU查TLB匹配VP
若TLB hit,且valid=1取物理页号,若valid=0,等同TLB miss
若TLB miss,MMU在页表中进行查找,得到PTE,将PTE加载如TLB
若PTE的valid=0,PageFault缺页,页不在内存,中断读硬盘并更新PTE
若脏则写回磁盘若有空闲页框PP1,PP=PP1 若没有,替换PP2
Flush
PP=PP2读内容,更新PTE,加入TLB
设计:需要空闲页框链表
纯硬件:不灵活、需更多空间保存页表
进程切换:若有pid标签,则修改TLB寄存器和进程寄存器的内容;否则作废整个TLB
修改页表项:指修改tag,换出,上下文切换,Exec
需修改内存中的PTE和把对应TLB表项设为无效(TLB flush) - Cache vs. TLB
相同:缓存、不命中则替换
不同:关联度,一致性(缓存:侦听协议;TLB:无脑flush) - 页替换算法
最优算法(MIN)
若知道未来的访问情况,则替换最不可能访问的
适用于离线分析
例:若内存4个页,访问序列123412512345,则6个缺页
NRU
按顺序随机选择页:非R且非M、非R且M、R且非M、R且M
例:上述例子7个缺页
缺点:需扫描内存中所有页的RM位
FIFO
选择最老的页扔掉
好处:开销小
坏处:频繁适用的页被替换
例:上述10个缺页(若内存3个页,只9个缺页)
Second Chance
检查最老页,R为0,替换;否则,清零并移动到队尾,继续查找
好处:简单
坏处:最坏情况可能需要很长时间
例:8次缺页
Clock
环形链表,指针检查,R为0替换;否则置0,指针前移
好处:开销小,实际的解决方案
双表针Clock
前表针扫描把R清零,后表针把R为0的页加入替换链表
表针间距:页框再次被访问的时间窗口,控制页在内存的最长停留时间
扫描速度:是替换速度,空闲内存小,扫描速度快
LRU
链表,替换LRU的页并置顶为MRU
Hit也置顶
矩阵表示法:访问页框k时,把k行的位置1,k列的位置0,自己置0;找二进制行数最小的行
例:8个缺页
好处:对MIN算法的很好近似
坏处:实现困难
近似LRU
记录每页访问时间戳(硬件的指令计数器),替换时间戳最小的页
坏处:开销大
NFU
记录每页的访问次数(软件模拟,时钟中断时所有页计数器与R值相加),替换访问次数最小的页
例:8个缺页
坏处:过去频繁的页不能被换出
Aging
时钟中断时,页计数器右移1位,再最高位与R位相加
记录的历史更短,无法区分访问的先后顺序
好处:对LRU的较好近似
工作集
定义:最近K次访问的那些页
近似:一个进程在过去T秒内使用的页
算法:记录页的上次访问时间;替换时扫描所有页,若R=1则置0且更新访问时间;若R=0则计算时间差Δ,若大于T 则替换(脏页面调度返回)。更新缺页的页到工作集。有多个R=0则淘汰生存时间最久的;若全为R=1则随机选不脏的替换
缺点:实现困难
WSClock
表针扫描,若R=1,置0更新时间;若R=0,Δ>T,M位为0,替换 - 虚存设计问题
页大小
大页:页表小,磁盘IO高效;内部碎片
解决:内核用大页,用户进程用小页
模拟PTE的控制位
M位:用R/W模拟
用预留位记录页的ReadOnly状态,把R/W设为ReadOnly
对页写时触发Page fault(Write fault),如果不是ReadOnly则M设1
R位:用V位模拟
用预留位记录页的V位,设V为0
访问页时触发page fault,若预留V=1,则置R为1,加入LRU链;若不在内存,进行页替换 - 颠簸:频繁发生缺页
现象:进程被阻塞,访存速度慢
原因:进程工作集>可用物理内存;进程过多
解决:不活跃组进程(等待事件或资源)的工作集不放内存,新增长期调度器决定哪些进程是活跃进程 - 替换哪个进程的页框
全局选择:所有进程的页框选择
优点:简单
缺点:没有隔离,受其他进程干扰,不能控制各进程使用量
局部选择:从本进程选择(工作集或WSClock算法)
优点:隔离
缺点:不灵活,进程内存可用量固定,增大会颠簸
平衡分配:局部选择+页框池大小动态调整
进程换入时,先预载初识池大小的部分页减少page fault,如果等于工作集大小会更快
初识池大小分配:固定、余量平均(差异大)、进程大小按比例
动态调整:PFF算法(缺页率PFR高于A则增加内存,低于B则缩小内存)
PFR:上一秒缺页数或滑动均值
何时调整:发生缺页时 - 钉住页
原因:DMA需要被传输的页
记录所有被钉住的页 - 交换区:存储进程换出页
管理方法
静态
创建进程时分配,结束时回收,大小等于进程image
一个虚存页对应一个磁盘页shadow page
初始化:按需换入或按需换出
缺点:不灵活、难增长
动态
页换出时分配,换入时回收,虚页与磁盘页不绑定
PTE中记录页的磁盘地址
优化:把程序段用ELF文件代替
换出:页拷贝,磁盘页号DP填入PTE,把PTE和TLB置无效
换入:找空闲页框并拷贝,PP填入PTE,把PTE和TLB置有效 - 页清零:第一次page fault时
- 页共享
- 写时复制
适用于fork
把所有页设为ReadOnly,在子进程写时创建新页 - UNIX地址空间
数据段:初始化数据、未初始化数据BSS(Block Started By Symbol),用brk更改
栈段
内存映射文件:mmap把文件映射入内存 - LINUX内存管理
伙伴系统
缺点:内部碎片
Ch5 IO设备
- IO硬件包括:IO总线、设备控制器、IO设备
设备控制器
主机接口(信息传递)、控制寄存器、数据缓冲区 - IO寻址方式
IO端口:只能IO指令访问、独立地址空间(地址线指示)
内存映射IO:统一地址空间(CPU发出地址,所有内存模块和所有设备都要解析)
优点:编程方便、保护灵活、指令少
问题:cache不能缓存、专用内存总线(IO设备不能查看内存地址) - 传输数据的粒度
字符设备,传输大小可变
块设备,固定块为单位 - IO软件层次
用户级IO软件
与设备无关的OS软件:分配设备与空间、缓冲、错误报告
设备驱动程序
中断处理程序 - 传输数据的方法
PIO轮询
中断
DMA
适用于:中断缓慢、字符很多
同步操作
OS检查正确性,调用驱动
驱动分配buffer,启动DMA(等待设备就绪,清除就绪,设置DMA参数),阻塞当前进程
DMA传输完成,发中断,唤醒线程
驱动检查结果正确性
系统调用拷贝数据,返回用户进程
异步操作
OS检查正确性、挂到异步请求队列、返回
内核的异步线程取队首调用驱动
驱动启动DMA,阻塞异步IO线程
DMA传输完成,发中断,唤醒异步IO线程
驱动检查结果正确性
异步IO线程拷贝数据
字模式:周期窃取;块模式:突发模式 本质:CPU和DMA不能同时占总线 - 设备驱动
给OS的其他模块提供操作设备的API,与设备控制器交互
接口
Init初始化硬件
Open初始化驱动,分配资源
Close 回收资源并关闭设备
Read、write、块设备还有seek(控制器控制磁头移动,对驱动透明)
流程
准备工作
操纵设备、阻塞等待
错误处理
返回调用者 - 安装驱动方式
静态(重启OS)
动态挂载
间接指针(设备入口点表)
驱动加载进内核空间
关联入口点
初始化设备驱动
优点:灵活性
缺点:安全性,设备驱动在内核态 - 磁盘
扇区
头部(ID)数据区:512B 尾部(ECC校验码)
磁盘缓存
针对随机读写
由控制器管理,替换策略:LRU
调度算法
FCFS
寻道距离可能长
SSF
选择磁头移动距离最短的请求
坏处:饥饿
SCAN电梯调度
磁头单方向移动,再折回
LOOK:如果之后没请求,直接折回
消除饥饿
C-SCAN
折回时不服务
服务时间趋于一致 - RAID
RAID0
可靠性等于相乘
带宽N倍
延迟为单个延迟
RAID01
容量=N倍/R
可靠性:最多容忍N/2块盘坏
写带宽:N/2倍 读带宽:N倍
读延迟:单个延迟 写延迟:略大于单个
RAID2 位为粒度+ECC海明码 6b奇偶校验
RAID3 位为粒度+Parity位 1b
缺点:需要硬盘同步
RAID4
缺点:校验盘易坏
写校验盘方法:读校验盘+新盘Pnew=Bold XOR Bnew XOR Pold
读延迟:单个延迟 写延迟:约两个盘
读带宽:N-1倍 写带宽:单个带宽/2
RAID5
校验块分散不同盘
写带宽:校验块并行写=N/4倍 - 卷管理
虚拟块设备
RAID将逻辑卷的块地址映射到物理设备 - 存储系统的演进
企业:分布式系统 - 闪存
全电子器件,无机械部件,非易失
NAND(大容量持久化存储)
NOR(更快,替代ROM)
层次结构:Flash->Die->Bank->块(MB,读写粒度)->页
页
数据区+OOB(ECC、状态信息)
大小:4KB-16KB
操作接口
状态:invalid,erased,valid
Read:粒度为页,延迟低(几十us),延迟与位置无关
Erase:整个块全置1,慢(ms),状态变为Erased
Write:擦除后才能写,粒度为页,比读慢(几百us),状态变为Valid
可靠性:磨损、干扰(读写一页,相邻页中部分位翻转)
FTL方式
直接映射
读很快,写很差(读块、擦除块、写块)
页级映射
写到新位置上,建立映射表(暂存内存,保存在OOB区)
优点:性能好,可靠性
缺点:内存开销大;重写不覆盖无效原页(垃圾页)
块级映射
Chunk等于物理块大小
逻辑页地址=chunk号+偏移,chunk映射到块base
缺点:写粒度小于块,需拷贝活页,写放大
混合映射
分数据块、日志块
写块被记录进日志块,适当时合并为数据块,原数据块擦除
数据块用块级映射
日志块用页级映射
读块时先查日志映射表,再查数据映射表
回收日志块:若日志块顺序与原数据块不一样,则需一起拷贝到新块上
优点:开销低,数据拷贝少
垃圾回收
选择含垃圾页的块,拷贝活页,擦除块
活页:若映射表PPN=该页
缺点:时间长
磨损均衡
动态:每次写时,选择擦除次数最少的块
静态:长时间不再修改的冷快,FTL定期重写
Ch6 文件系统
- 概念
文件:命名的字节数组,内容无结构
类型:常规文件、目录文件、设备文件、可执行文件
属性:大小、所有者、时间戳、权限
目录:特殊的文件,文件组织的单位
目录项为文件名到ino的映射表
I_mode区分
文件描述符表
打开文件位置、访问方式
名字空间:属性层次结构,文件系统的逻辑视图 - 接口
文件:Create, unlink删除, open, close, read, write, lseek, truncate, stat属性
Open流程:路径名解析得到ino,得到inode,拷贝至内存,创建打开文件描述符fd,PCB分配空闲指针指向fd,返回fd
目录:mkdir, rmdir, open, close, readdir, link, symlink, rename
FS:mkfs, rmfs, mount, umount, sync同步, df获取属性
Mount条件:FS类型已知,目录已创建
流程:查VFS开关表找到并调用初始化函数 - 文件访问模式
顺序访问(依次访问每个文件块,和顺序访问扇区不一样)、随机访问、按关键字访问 - 硬链接
多用户共享同文件,可有多名字,指向同一inode
不能对目录做链接 - 符号链接
Shortcut - 磁盘布局
Bootblock
Superblock:定义FS
块大小数量使用情况、inode大小数量使用情况
根目录ino
Inode表起始位置,空闲数据块指针,空闲inode指针
BlockBitmap
InodeBitmap
InodeArray
DataBlock - 虚拟文件系统VFS
规定API,挂载多类型FS - Inode
Ino
I_mode
Size
Nlinks硬链接数
Uid,gid
Ctime,atime,mtime - 文件块索引
连续分配:实现简单、顺序访问性能好;不灵活、外部碎片
链表结构:块粒度、随机访问性能差、可靠性差
文件分配表(类似链表):简单;FAT空间消耗、随机访问性能差
单级索引:文件可变大、随机访问性能高(数据块直接定位);不灵活
两级索引:支持文件10GB;不灵活、外部碎片
UNIX:10直接,1一级间接,1二级间接,1三级间接
优点:小文件访问方便、支持文件大
缺点:文件有上限、大量寻道
Extents:
不定长的连续分配
inode记录B树的根节点地址 - 名字空间管理
文件名与inode分离存储,文件名保存在目录项中
创建文件/目录:
父目录路径解析、权限检查、检查文件是否存在、创建文件(空闲inode、添加目录项、更新父目录inode)
删除文件/目录:
父目录路径解析、权限检查、检查文件是否存在、删除(nlink–,若为0则删除,删除目录项,更新父目录inode) - 目录项的组织方式
线性表
优点:空间利用率高
缺点:大目录性能差、删除紧缩耗时
B树,以文件名排序
优点:大目录性能高
缺点:小目录不高效、空间占用大、实现复杂
哈希
Hash(filename)->ino
优点:查找快
缺点:大目录效率不如B树、空间占用 - FS vs. VM
相似:用户透明;固定粒度;保护
FS更容易:可以慢、可以顺序访问
FS更难:每层解析都要IO、文件长度差距大、可靠性
FFS BSD
分大文件块和子块(512B)
大文件:直接指针和inode放在同CG,间址块和指向的块放在同CG
用位图取代空闲块链表,连续分配:大粒度访问
把磁盘划分为柱面组CG,多个subFS,目录均衡放置
优化空间:extents、异步写、日志
效果:提高IO带宽、减少长距离寻道
创建新文件:修改inode bitmap,写inode,修改父目录项,更新父目录inode,修改bb,写文件块 - 文件缓存
位于内核空间,多用户共享
替换策略:全局LRU
预取:访问第i块预取后k块;读取目录项时预取inode;预取同一目录下的所有小文件 - 可靠性
威胁:设备坏、掉电
物理备份:设备级
逻辑备份:FS级 全备份、增量备份
先写元数据,后写数据
获得inode,写bitmap(不能掉电),更新inode(不能掉电),写数据块
若在写完元数据之后,且写数据之前宕机,元数据所指向的数据块内容不正确
先写数据,后写元数据
获得inode,修改bitmap(不能掉电),写数据块,更新inode
若写数据后,写inode前宕机,则元数据指向旧版本,保持修改前的状态
自底向上
文件的数据,文件的inode,父目录的数据,父目录inode,…
缺点:写性能差,FS不一致:宕机产生垃圾块
解决:fsck检查FS一致性、superblock、bb、inode、nlink域、数据块冲突、数据块越界
恢复磁盘布局component
启动块:复制启动块到U盘
超级块:多副本
空闲块结构:重新扫描 - 事务
A原子性
C一致性(事务完成后所有状态必须是正确)
I隔离性
D持久性 - Write-Ahead Log
备份顺序:开始事务TxB、commit结束事务TxE、Checkpoint修改磁盘、清除日志
开销:两倍写
优化:只记录inode修改的日志,只需一倍写
缺点:频繁写磁盘 改进:批量提交(可能损坏数据,不损坏FS)
无法应对硬件故障
空间 改进:定期checkpoint
宕机恢复:若磁盘上没有结束日志TxE,则无行动;否则按日志重做,然后清除日志
Checkpoint:commit后把修改全部写到磁盘上
Checkpoint完成后清除日志
使用前提:日志中所有修改是幂等的;事务唯一编号TID;能确认写磁盘完成 日志文件系统 – Logging File System
优点:写日志是顺序访问,可以提高性能
方式
数据日志
写流程:TxB、inode日志、bitmap日志、数据块日志、TxE
在Checkpoint时真正修改
开销:所有数据块写两次磁盘
元数据日志
写流程:写数据块、写inode和bitmap日志
创建文件:修改inode bitmap,写inode,写父目录的第一块(日志),更新父目录inode
写流程:写日志到新位置LFS – Log-Structured File System
无需bitmap管理空间,文件块用多级索引
Segment:大粒度的内存buffer,可缓存多次写
Imap:记录ino->inode地址
一致性:先写文件块,再写inode(无固定位置)
消除对磁盘的小粒度随机写和同步写,用大粒度顺序写磁盘
重写和修改产生垃圾,垃圾回收
写流程:写入一块日志,包含文件块,inode和imap分布式文件系统
如何访问远程文件:FTP、DFS
NFS
多客户端:实现FS功能和接口,系统调用转换为请求服务器
单服务器:接收请求,读写本地FS
核心:无状态服务器(不记录C打开的文件)
File Hangle标识客户端要访问的文件
服务器目录可挂载到Client,提供服务器和路径名,返回FileHandle
操作:Lookup(返回文件的FH)Read、Write、GetAttr
客户端Open时关联fd和FH,close时无交互
失效处理:Retry
客户端缓存:一致性:open时检查缓存块有效期,脏数据及时写回
服务器缓存:可能宕机,要及时WRITE+COMMIT
WAFL
存数据 4KB块
<=64B 直接存inode
<=64KB 存16个直接指针
<=64MB 存16个一级间接指针
其余 存16个二级间接指针
快照 - 文件系统的只读版本
元数据块写在文件中
可COW创建快照,写时复制
恢复:到最后一个一致点,用日志恢复到宕机前
改进:日志写入NVM,满后写回磁盘
创建快照的步骤:把脏块标记为in-snapshot不能修改;分配空间;写回inode;更新block map file;刷回脏块;复制根inode
删除快照:删除根inode;清除blockmapfile的位
Google File System
客户端:库函数接口(用户态,区分GFS和本地FS)
多Chunk Service存储GFS,固定粒度64MB
每个Chunk存储多个副本,自动复制,自动容错
单一Master存储元数据和命名空间,全放内存
副本一致性:三阶段写(获得服务器位置、传输数据、S写入文件)- 安全与保护
数据机密性、完整性、可用性
保护机制
Authentication
验明身份
Authorization 决定A是否允许做某事
ACL 访问控制表